|
Han Yi Hello! I am currently a second-year CS PhD student at the University of North Carolina at Chapel Hill (UNC), under the guidance of Prof. Gedas Bertasius. I completed my Master's degree at the National University of Singapore (NUS) in 2024. During my time at NUS, I also served as a research intern at the NExT++ Research Center, where I was advised by Prof. Tat-Seng Chua, Prof. Zhedong Zheng, and Prof. Xiangyu Xu. I love basketball, football, rap music, and fitness. Email / CV / Google Scholar / Github |

|
ResearchI'm broadly interested in advanced Computer Vision and Multi-modal Learning, with a focus on both the fine-grained understanding and generation of complex human actions, particularly in the area of sports. I also work on leveraging foundation models (LLMs, VLMs, etc.) to solve multiple video understanding tasks. |
|
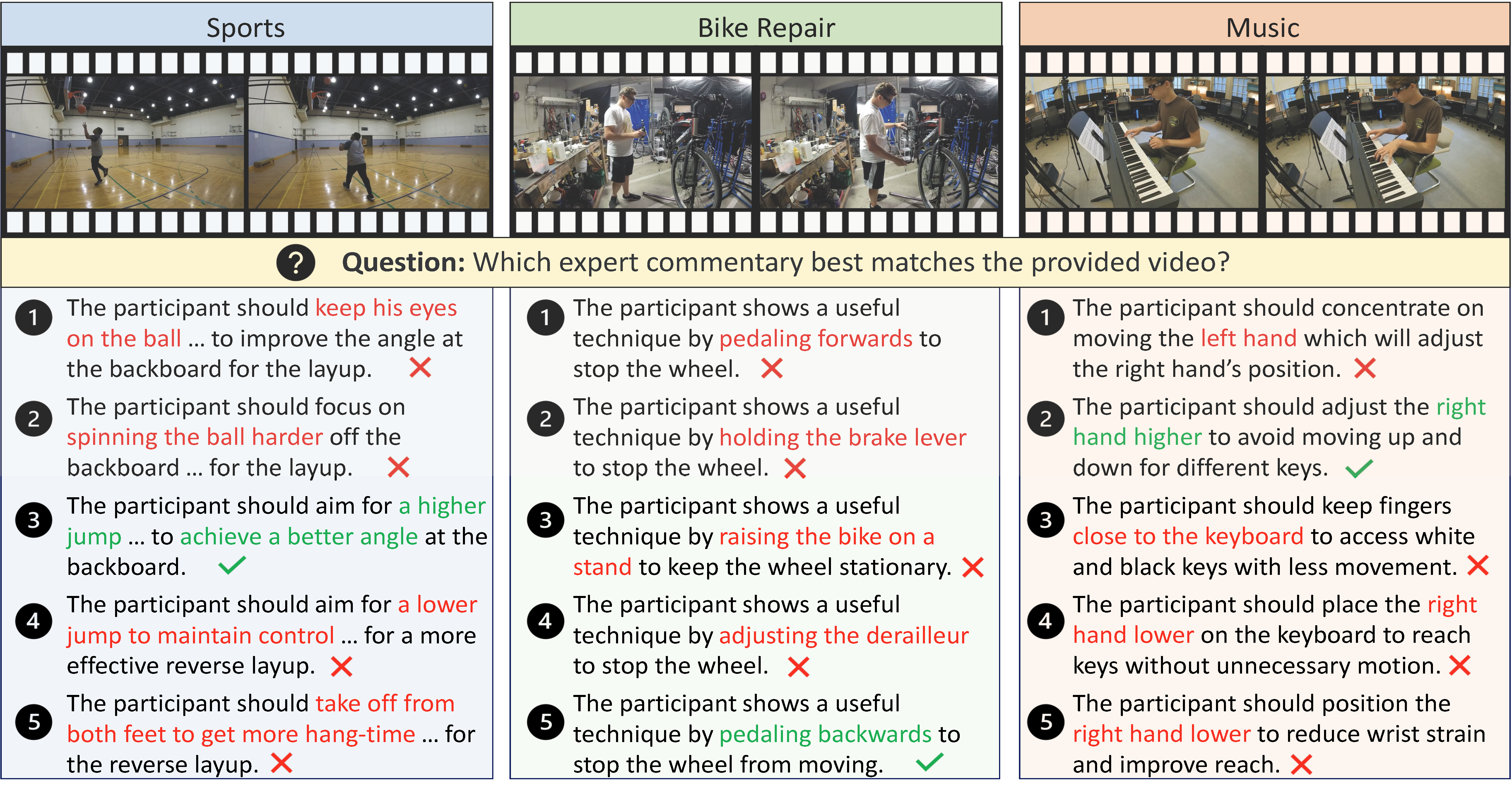
ExAct: A Video-Language Benchmark for Expert Action Analysis
Han Yi, Yulu Pan, Feihong He, Xinyu Liu, Benjamin Zhang, Oluwatumininu Oguntola, Gedas Bertasius NeurIPS, 2025 Project Page / Paper / Data We introduce ExAct, a video-language benchmark for expert-level analysis of skilled human actions. It contains over 3,500 expert-curated video QA pairs across domains like sports, cooking, and music. Our benchmark reveals a significant performance gap between state-of-the-art VLMs and human experts, highlighting the need for models with a more nuanced understanding of complex human skills. |
|
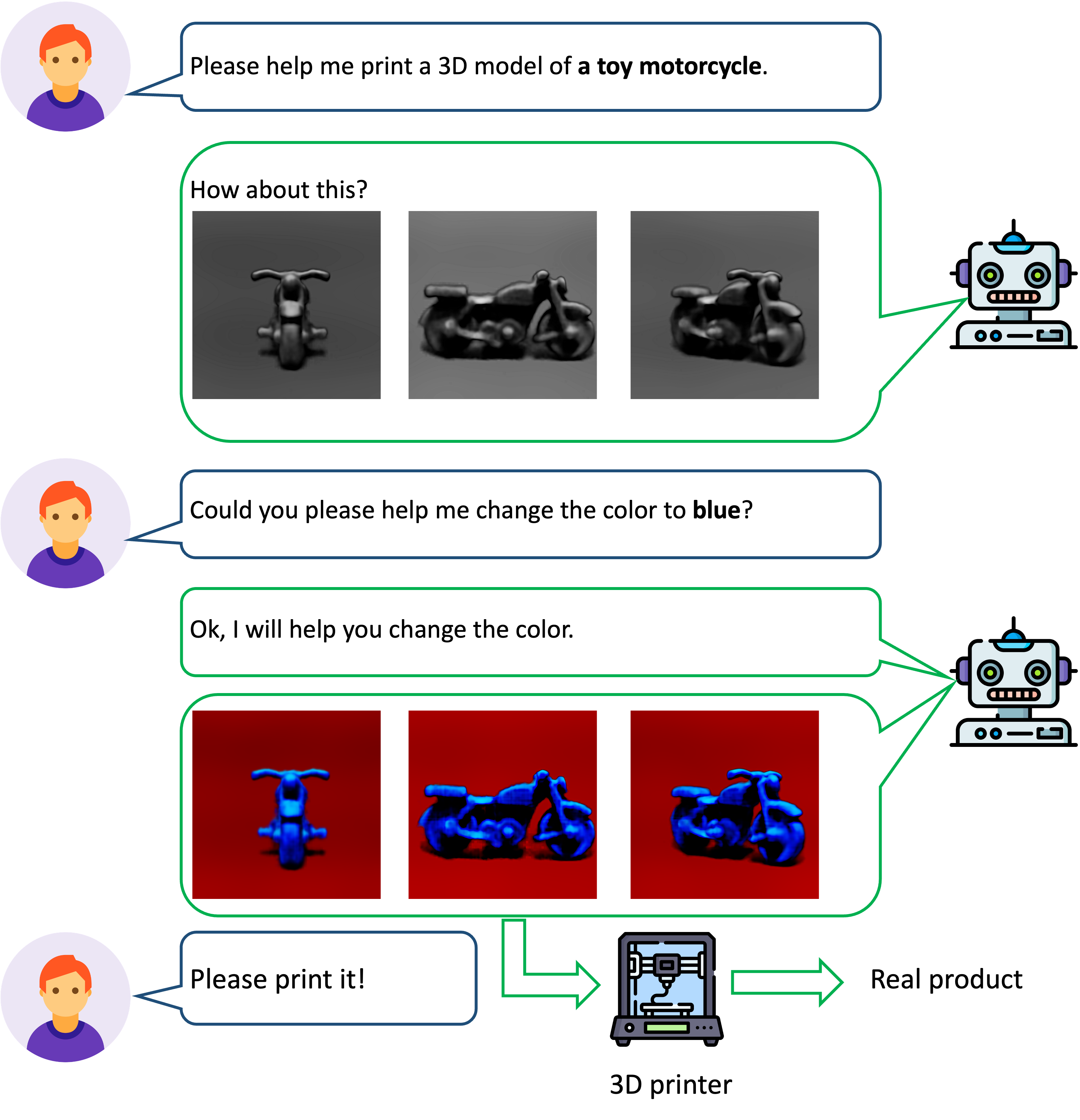
Progressive Text-to-3D Generation for Automatic 3D Prototyping
Han Yi, Zhedong Zheng, Xiangyu Xu, Tat-seng Chua arXiv, 2023 A progressive strategy that learns text-to-3D in a coarse-to-fine manner. |
|
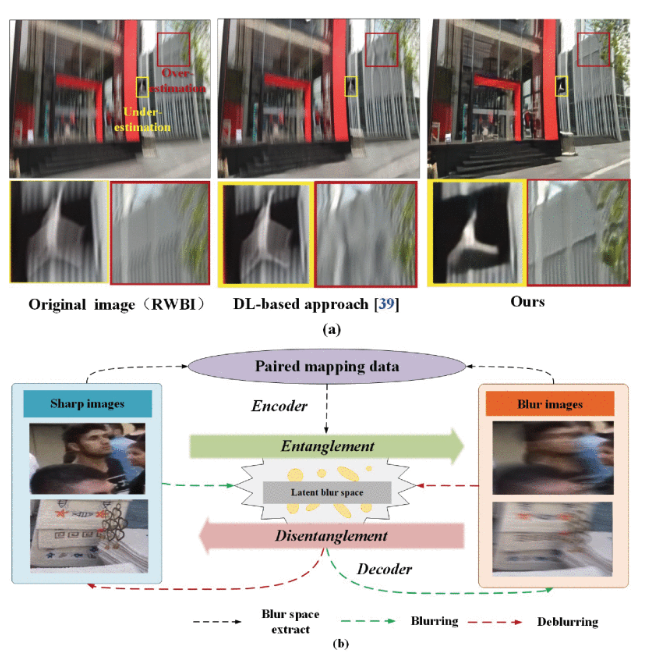
Image Deblurring With Image Blurring
Ziyao Li, Zhi Gao, Han Yi, Yu Fu, Boan Chen IEEE Transactions on Image Processing (TIP), 2023 Proposed a novel motion deblurring framework using Blur Space Disentangled Network (BSDNet) and Hierarchical Scale-recurrent Deblurring Network (HSDNet) to effectively address real-world blur, achieving state-of-the-art results. |

|
Single image deraindrop leveraging luminance priors and context aggregation
Yi Liu, Zhi Gao, Tiancan Mei, Han Yi Neurocomputing, 2024 Developed a recurrent single-image deraindrop approach utilizing luminance priors and contextual feature aggregation, achieving superior performance in restoring color and texture consistency. |
Services
Reviewer: ICLR 2026, ICLR 2025, ACM MM 2025, ACM MM ASIA 2025, ACM MM 2024 (Outstanding Reviewer Award) |
|
This webpage is adapted from Jon Barron's page. |